
AI Joker: Las máquinas bromean
Tags: NLP, Language Model, Deep learning
Las máquinas no hacen gracia
Nos ha pasado a todos. Ya sea a Alexa, a Siri o al asistente de Google, todos alguna vez le hemos pedido a alguno de estos asistentes virtuales que nos cuenten un chiste. El resultado suele ser un chiste aleatorio preparado y por lo general bastante suave.
En este contexto, surge la siguiente hipótesis: ¿Podría enseñarle a una máquina a hacer chistes de temas concretos?
En este post pretendo dar una visión técnica sobre cómo atacar esta hipótesis.
Disclaimer: Usaré de forma indistinta “palabra” y “token” porque en el contexto de este proyecto son equivalentes, pero esto no sucede en todos los casos.
Los datos
Como de costumbre, lo primero y más importante son los datos. Si has leído el post acerca de modelos de lenguaje, entonces algo que está claro es que vamos a necesitar muchos datos si queremos entrenar un modelo de lenguaje.
En este caso, después de buscar recursos online que pudieran ser útiles, dí con este repositorio, que nos proporciona 3 ficheros con muchos chistes en inglés extraídos de internet, y además también los distintos scrapers que los han generado en forma de scripts de Python. De los 3 ficheros con chistes ya extraídos hemos usado sólamente los siguientes dos:
- Banco de chistes de Reddit: 195.000 chistes, ~7.400.000 palabras.
- Banco de chistes de Wocka: 10.000 chistes, ~1.100.000 palabras.
Los dataset tienen formato JSON, con objetos como el siguiente:
{
"title": "If I get a bird I'm naming it Trump",
"body": "cuz all they do is Tweet",
"id": "5tyyo2",
"score": 1
}
Preprocesado
Siendo un proyecto personal sin demasiada transcendencia, no me compliqué demasiado la existencia en el momento de preprocesar/limpiar el texto y prepararlo para ser usado como entrada para entrenar el modelo.
Principalmente el preprocesado que hice al texto de los chistes es, quitar todos los signos de puntuación (excepto el apóstrofe, que en inglés es fundamental), y convertirlo todo en minúsculas.
Vocabulario
Hay una decisión importante que tomar: ¿Qué presupuesto de vocabulario nos vamos a poner?
Un presupuesto bajo en vocabulario (p.e. 1000) implicará que el modelo sólo entenderá las 1000 palabras más frecuentes entre las ~8.500.000 totales (99.914 distintas) que tenemos en el dataset, pero el resto no. Eso podría suponer generar chistes sin sentido por falta de palabras concretas que no sean excesivamente frecuentes.
En cambio, un presupuesto muy alto o ilimitado nos incrementará la cantidad de parámetros del modelo muchísimo sin necesidad, puesto que tal vez estemos teniendo en cuenta palabras que aparecen 1, 2 o 3 veces entre todos los chistes.
En este sentido, por una lado nuestra matriz de embeddings tiene tamaño VxE (dónde V=tamaño de vocabulario, E=tamaño del vector/embedding), por lo que cada palabra distinta podría añadir E parámetros más al modelo.
Además, como que un modelo de lenguaje quiere predecir la siguiente palabra, se entrena como clasificador con tantas clases como palabras distintas conoce, por lo que el tamaño del vocabulario tendrá importante influencia en la cantidad de parámetros de la capa de clasificación final.
En este caso, el presupuesto lo definí en 10.000 de forma arbitraria. Idealmente se debería analizar más profundamente las métricas de frecuencia de palabras en chistes, y las capacidades de computación disponibles para establecer un presupuesto óptimo.
En este punto, las palabras que se escapan al presupuesto se sustituirán por un token genérico “<unk>”, que terminará dando lugar a un embedding bastante inespecífico. Además, añadiremos los tokens de control “<pad>” y “<endtoken>” para homogeneizar el tamaño de la entrada y controlar cuando se terminan los chistes respectivamente.
Tamaño de los chistes
Como restricción obligada por la tecnología actual, debemos establecer un límite de palabras a los chistes. Después de hacer un análisis en el conjunto de datos, obtuve el siguiente histograma (x: cantidad de palabras, y: cuántos chistes tienen esa cantidad de palabras).
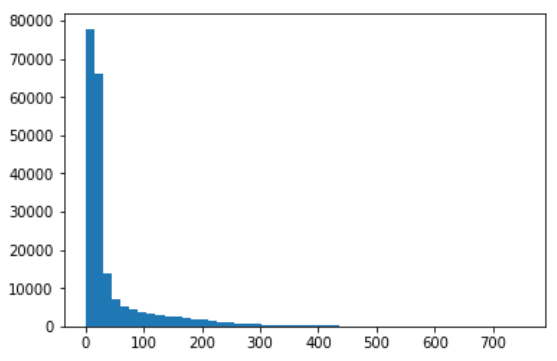
Viendo lo siguiente, ví que el promedio de longitud de chistes eran de 45 palabras, y que aproximadamente el 80% de los chistes no alcanzaban las 50 palabras, por lo que el límite lo puse allí. Como he comentado, los chistes más cortos van a recibir padding, y los más largos terminarán siendo cortados.
Caracterización (Featurization)
Como muchos modelos de Deep Learning sobre texto, la caracterización en este caso se va a basar en el uso de word embeddings, es decir, vectores numéricos que representan a cada palabra, e intuitivamente aportan información semántica.
Estos word embeddings pueden, o ser entrenados juntamente con el modelo (lo que suele dar embeddings orientados a la tarea que se pretende resolver), o bien se puede partir de embeddings que la comunidad haya entrenado previamente. En este caso, debido a que el lenguaje usado en chistes es un lenguaje de dominio general, opté por esta segunda opción, y he partido de los embeddings preentrenados mediante GloVe (de Stanford).
Una vez sabemos cómo vamos a representar cada palabra, hace falta generar los datos finales, las dos matrices que usaremos como datos de entrada. El secreto en este caso es que la predicción es la misma entrada, pero desplazada en la dimension temporal un paso en el futuro. Es decir, como salida a la tercera palabra de un chiste, querremos que nos de la cuarta palabra del mismo chiste, y así para todas.
Modelo
Puesto que este proyecto tiene un tiempo ya, la tecnología que usé fue LSTM (Long Short-Term Memory), es decir, una red neuronal recurrente con mejoras para recordar mejor información pasada. Actualmente esta tecnología va siendo reemplazada por el uso de Transformers, no obstante, puesto que los chistes tienden a ser textos cortos, las debilidades de los LSTM respecto a los Transformer no deberían ser muy evidentes. Tal vez próximamente haga un artículo de RNN vs Transformers para modelos de Deep Learning sobre texto.
A partir de aquí, el modelo es bastante directo. Es un modelo secuencial, que recibe como entrada un listado de enteros (cada entero identifica una palabra), que luego serán sustituídos por el vector o embedding correspondiente, por lo que terminaremos con una matriz, en la que cada fila es el embedding de cada palabra que conforme la frase, y cada columna será una dimensión del embedding.
Este embedding será el que llegará al LSTM. Debido a que es un LSTM unidireccional, en el momento de procesar la palabra t del chiste, sólo tendremos el contexto de las palabras 0..t-1. Esto difiere del funcionamiento en otras tareas como NER, dónde el BiLSTM es más útil y nos permite explotar dependencias en el pasado y futuro.
Aunque en tiempo de entrenamiento tengamos acceso al futuro, en tiempo de predicción eso no será posible, por lo que nos vamos a conformar con tener contexto unidireccional. En este caso definí dos capas de LSTM unidireccionales, con 256 celdas LSTM en cada capa. De nuevo, hay mucho margen de maniobra con la cantidad de capas y de celdas por capa, pero de entrada esta complejidad me pareció adecuada.
En estas celdas LSTM apliqué un ratio de dropout del 25% con el interés de controlar posibles sobreajustes durante el entrenamiento y que siempre repitiera chistes vistos.
Finalmente, llegamos a la última capa, que en este caso es una simple capa totalmente conectada (fully-connected o dense) con tantas neuronas como tamaño del vocabulario (es decir, 10.003), con la función de activación softmax que nos permite que la salida sea una distribución de probabilidad para cada posible palabra en cada punto del chiste.
Entrenamiento
Para el entrenamiento se hicieron 4 rondas de 15 iteraciones, dedicando un 85% para entrenamiento y el 15% para validación. En este caso se entrenó en la plataforma de Google Colab. Como podéis ver en los logs, cada ronda tardó ~1:20h. En este caso podemos ignorar las métricas de accuracy, puesto que en el escenario de language modelling no es necesariamente una métrica relevante. Sería interesante analizar la perplexity.
Train on 173031 samples, validate on 30536 samples
Epoch 1/15
173031/173031 [==============================] - 384s 2ms/sample - loss: 1.9144 - accuracy: 0.3048 - val_loss: 2.6002 - val_accuracy: 0.2864
Epoch 2/15
173031/173031 [==============================] - 326s 2ms/sample - loss: 1.9052 - accuracy: 0.3062 - val_loss: 2.6049 - val_accuracy: 0.2849
Epoch 3/15
173031/173031 [==============================] - 325s 2ms/sample - loss: 1.8963 - accuracy: 0.3077 - val_loss: 2.5892 - val_accuracy: 0.2882
Epoch 4/15
173031/173031 [==============================] - 325s 2ms/sample - loss: 1.8883 - accuracy: 0.3090 - val_loss: 2.5858 - val_accuracy: 0.2887
Epoch 5/15
173031/173031 [==============================] - 323s 2ms/sample - loss: 1.8810 - accuracy: 0.3103 - val_loss: 2.5799 - val_accuracy: 0.2899
Epoch 6/15
173031/173031 [==============================] - 328s 2ms/sample - loss: 1.8738 - accuracy: 0.3117 - val_loss: 2.5779 - val_accuracy: 0.2903
Epoch 7/15
173031/173031 [==============================] - 325s 2ms/sample - loss: 1.8673 - accuracy: 0.3127 - val_loss: 2.5698 - val_accuracy: 0.2915
Epoch 8/15
173031/173031 [==============================] - 325s 2ms/sample - loss: 1.8611 - accuracy: 0.3137 - val_loss: 2.5708 - val_accuracy: 0.2917
Epoch 9/15
173031/173031 [==============================] - 324s 2ms/sample - loss: 1.8552 - accuracy: 0.3147 - val_loss: 2.5665 - val_accuracy: 0.2921
Epoch 10/15
173031/173031 [==============================] - 323s 2ms/sample - loss: 1.8498 - accuracy: 0.3159 - val_loss: 2.5598 - val_accuracy: 0.2933
Epoch 11/15
173031/173031 [==============================] - 323s 2ms/sample - loss: 1.8445 - accuracy: 0.3165 - val_loss: 2.5625 - val_accuracy: 0.2934
Epoch 12/15
173031/173031 [==============================] - 323s 2ms/sample - loss: 1.8393 - accuracy: 0.3173 - val_loss: 2.5569 - val_accuracy: 0.2944
Epoch 13/15
173031/173031 [==============================] - 323s 2ms/sample - loss: 1.8349 - accuracy: 0.3183 - val_loss: 2.5549 - val_accuracy: 0.2945
Epoch 14/15
173031/173031 [==============================] - 323s 2ms/sample - loss: 1.8304 - accuracy: 0.3190 - val_loss: 2.5436 - val_accuracy: 0.2969
Epoch 15/15
173031/173031 [==============================] - 322s 2ms/sample - loss: 1.8259 - accuracy: 0.3198 - val_loss: 2.5468 - val_accuracy: 0.2962
Resultados
Sin invertir demasiado tiempo en la parte de preprocesado, arquitecturas de DL, hiperparámetros ni entrenamiento, tenemos un modelo que, por un lado, es generalmente capaz de redactar frases en inglés correctamente. También se nota que sólamente ha visto chistes, porque le des la entrada que le des, tiende a terminar el chiste de una forma “chistesca”, es decir, la forma de la frase resultante suele ser similar a muchos tipos de chistes conocidos.
En este sentido, podemos ver en cada palabra que va a generar, qué opciones considera, cómo valora cada una, y es alucinante ver que tiende a seleccionar palabras con todo el sentido del mundo, como podemos ver a continuación.
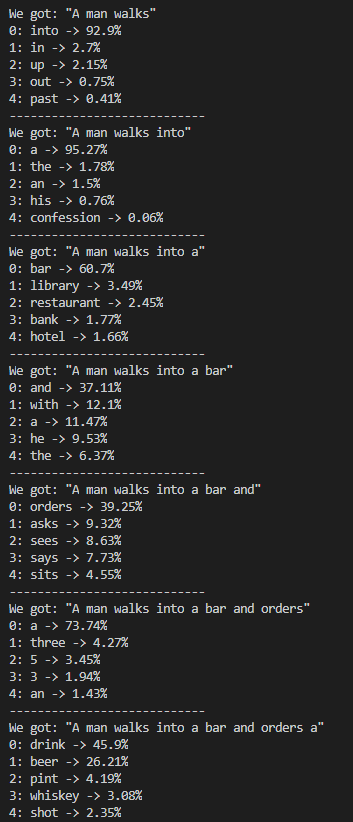
Aunque también tenemos la posibilidad de pedirle que se deje de intermedios y nos de el chiste final. Por ejemplo, para la entradilla “what is the” su resultado es:
Si bien es raro porque tiene no conoce los signos de puntuación, queda patente que sabe tanto escribir frases gramaticalmente correctas, y tiene esta tendencia de escribir en formas similares a muchos chistes.
Es importante remarcar, que puesto que internet tiene tendencia a ser machista, sexista y racista, fácilmente los chistes resultantes lo son también, por lo que no me hago responsable si luego los chistes ofenden a alguien… 🙄🤷🏻♂️
Demo
Disclaimer 1: Esto está desplegado como un contenedor de Docker en una app Heroku gratuita, puede que la ejecución sea lenta.
Disclaimer 2: Como recordatorio, el modelo sólo sabe crear chistes en inglés, la frase de entrada debería estar en inglés también.
Plug
Si después de leer esto te ha parecido interesante, puedes echarle un vistazo al código fuente del proyecto, que tengo publicado en github aquí. Consta de una parte de “Research” que está conformada por un Jupyter Notebook, y una parte de “Production” con un script mucho más definido para hacer pruebas.