
GPT3 y modelos de lenguaje
Tags: NLP, Language Model, Deep learning
El lenguaje
El lenguaje, y la capacidad de razonamiento que éste nos proporciona es el principal factor que convierte al ser humano en un ser inteligente. Gracias al lenguaje somos capaces de comunicarnos y de entender mejor el mundo. No obstante, la idea de que una máquina pudiera llegar a comprender y usar el lenguaje como lo hacemos nosotros siempre había sido más ficción que realidad. Por lo menos hasta ahora.
Cualquier lengua está regida por ciertas leyes estadísticas (p.e. ley de Zipf) y normativas lingüísticas (sintaxis, gramática, etc), por lo tanto, un modelo numérico sería susceptible de poder detectar patrones entre palabras o conceptos y seguir dichas leyes y normativas para comprender y generar textos.
GPT 3
GPT-3 es el último y más potente de los llamados “modelos de lenguaje” que ha sido impulsado por Open AI, compañía sin ánimo de lucro fundada por Elon Musk. Su objetivo básicamente es demostrar que las máquinas no solamente son capaces de comprender lenguajes humanos (como el inglés), sino que también son capaces de hablarlo.
La tarea que debe cumplir un modelo de inteligencia artificial de este tipo es aparentemente simple: Partiendo de una frase a medias (una o más palabras), el modelo debe decidir cuál es la palabra que debe continuarla. Repitiendo esta operación múltiples veces los modelos son capaces de generar frases o documentos enteros.
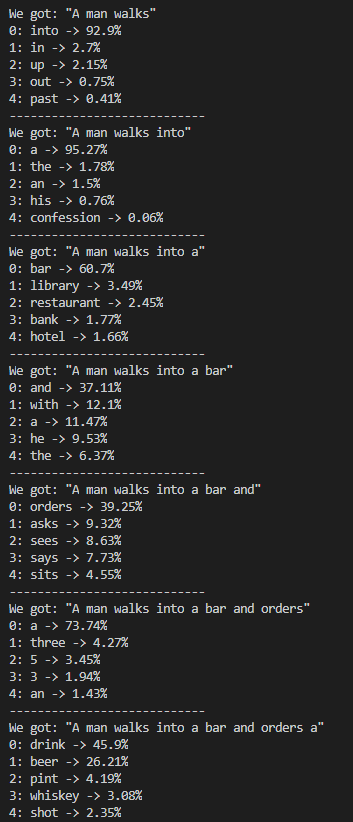
No obstante, aunque para cualquier persona esta tarea es sencilla, para las máquinas esconde una complejidad mucho más alta de lo que parece. Para poder decidir qué palabra sigue a una frase no terminada, se requiere de comprender el significado de las palabras que la componen, y el contexto en el que aparecen. Las personas adquirimos esta habilidad de comprender mediante el aprendizaje y la experiencia, y, en el caso de las máquinas, el proceso es sorprendentemente parecido.
Los modelos de aprendizaje profundo (Deep Learning) que consiguen buenos resultados en estas tareas lo hacen gracias a la observación (o “lectura”, si queremos humanizarlo) de ingentes cantidades de texto. Este proceso de observación recibe el nombre de entrenamiento.
Cuando hablamos de que requiere de ingentes cantidades de texto, nos referimos a, desde centenares de miles, hasta miles de millones de palabras (en el caso específico de GPT-3 alrededor de 500.000 millones de palabras), y siempre con el objetivo de aprender por qué cada palabra ha sido escrita, en base a las que la han precedido.
El resultado de este entrenamiento es un modelo que es capaz de asociar un significado a cada palabra (en forma de representación numérica llamada embedding), y a más bajo nivel, puede generar una representación numérica para comprender el contexto del conjunto de texto que se le da (a partir del significado de cada palabra). En base a este contexto, los modelos tienen la capacidad de predecir qué palabras son las que mejor encajan para seguir el texto.
Conclusiones
El hecho de que estos modelos puedan generar texto coherente los convierte en herramientas poderosas y útiles en distintos escenarios, como en las funciones de autocompletar que existen en ciertos buscadores y editores de texto, la funcionalidad de teclado predictivo disponible en los teléfonos móviles inteligentes, y cada vez más se extiende en muchos otros sectores y negocios como por ejemplo en el periodismo, con la redacción de noticias o generación de resúmenes automáticos.
Aunque hay que tener en cuenta que como muchas otras tecnologías parecidas, también puede ser una arma de doble filo, puesto que su uso malicioso para la generación y divulgación de fake news o la suplantación de identidad es algo que según vaya mejorando este tipo de tecnologías nos vamos a terminar encontrando.
Experimentos
Personalmente he desarrollado varios modelos de lenguaje, entre los cuáles destacaré un par.
El ejemplo de la imagen que he publicado en este artículo se corresponde a un proyecto personal en el que partiendo de 194.500 chistes extraídos de Reddit he entrenado un modelo de lenguaje basado en LSTM (del cuál hablaré en más detalle aquí), para que aprenda a generar chistes dadas unas pocas palabras.
Por otro lado, también he desarrollado otro modelo de lenguaje, esta vez basado en Transformer-encoders, que aprende de unos 45.000 artículos de la Wikipedia en español extraídos mediante un scraper (del que hablaré en este artículo).